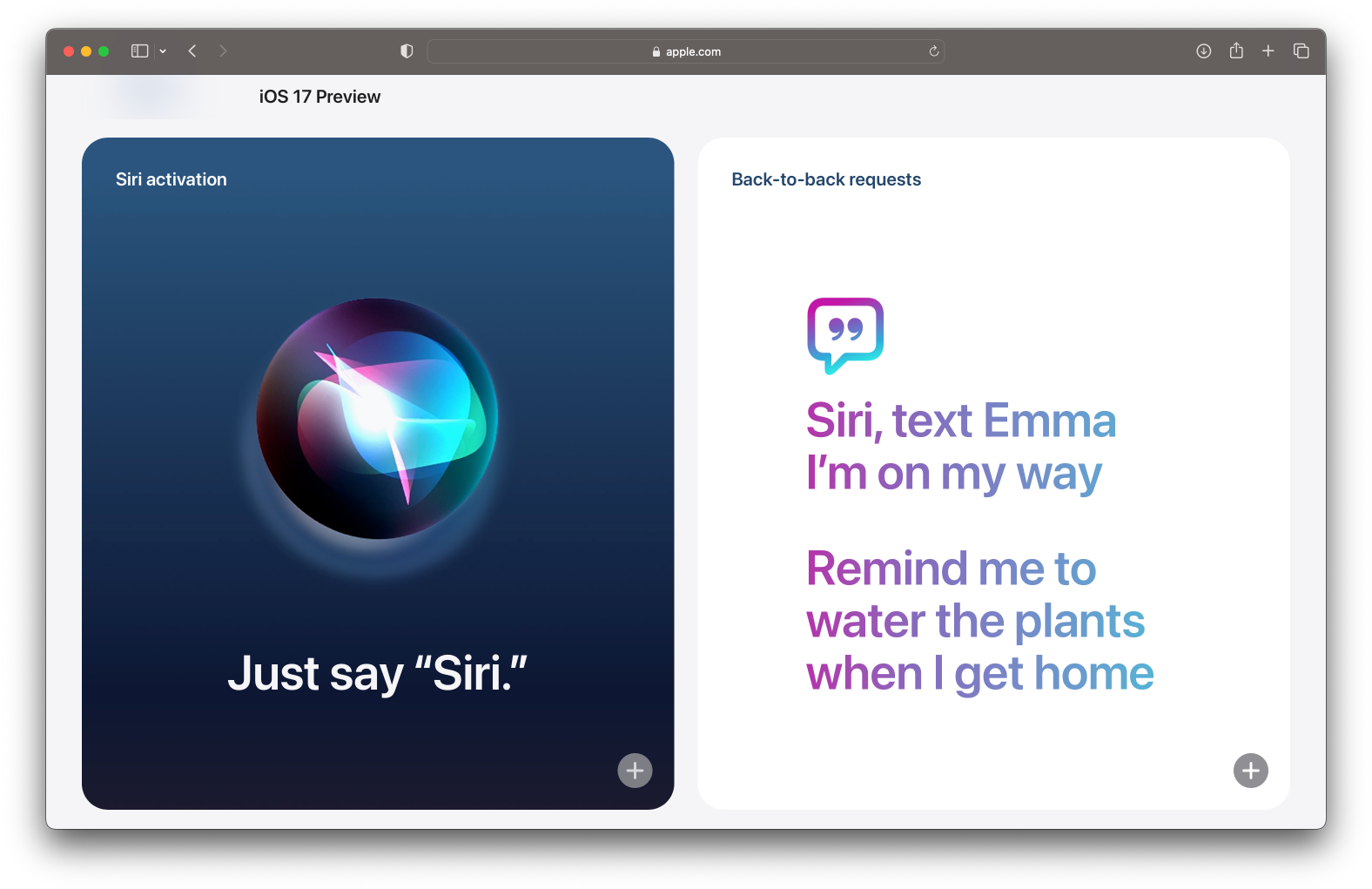
People want Siri to be easy to talk to, but unobtrusive. To put it another way, you want it when you want it, and you don’t when you don’t. This poses challenges given that Siri’s hardware button is overloaded — short press for screen lock, double-press for Wallet, and long press for Siri. And using just your voice to summon Siri is natural and convenient, but that convenience comes at the cost of occasional false-activation blunders.
Finding the right balance between these opposing poles — accessibility and unobtrusiveness — was at the heart of my work as the designer responsible for the mechanics of the conversation with Siri, including multimodal feedback about Siri’s state. For example: listening, processing, or ready for additional input from the user. (That’s just a high-level summary; it gets more complicated than that.)
The goal is, of course, an interface that feels fluid and responsive even though the microphone isn’t always (fully) on. There’s a surprising amount of technical sophistication behind the simple removal of the requirement to say “Hey” before “Siri” (debuting for English in iOS 17), but the gain in fluidity and confidence that this affords users is tremendous.
But doing more with less speech signal is only the tip of the invocation iceberg. My team and I collaborated with acoustics, computer vision and location/ranging researchers to build sensor fusion techniques that can model natural engagement and disengagement behaviors across a wide range of devices and scenarios.
Our contributions included vision videos/Keynotes, diagrams and audiovisual mockups at the turn and micro-turn level, policy briefs, Setup and Settings UI, and copy.
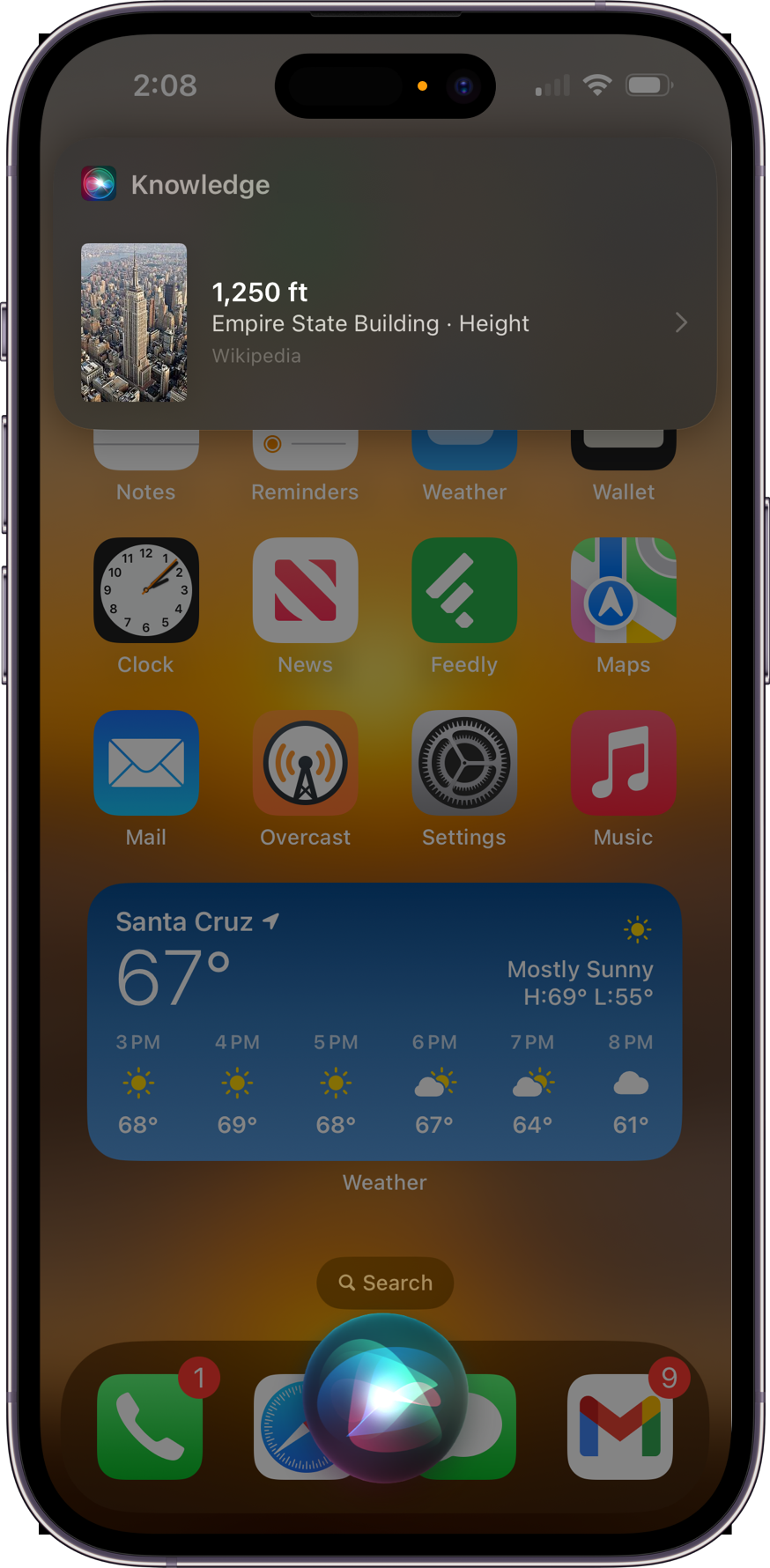
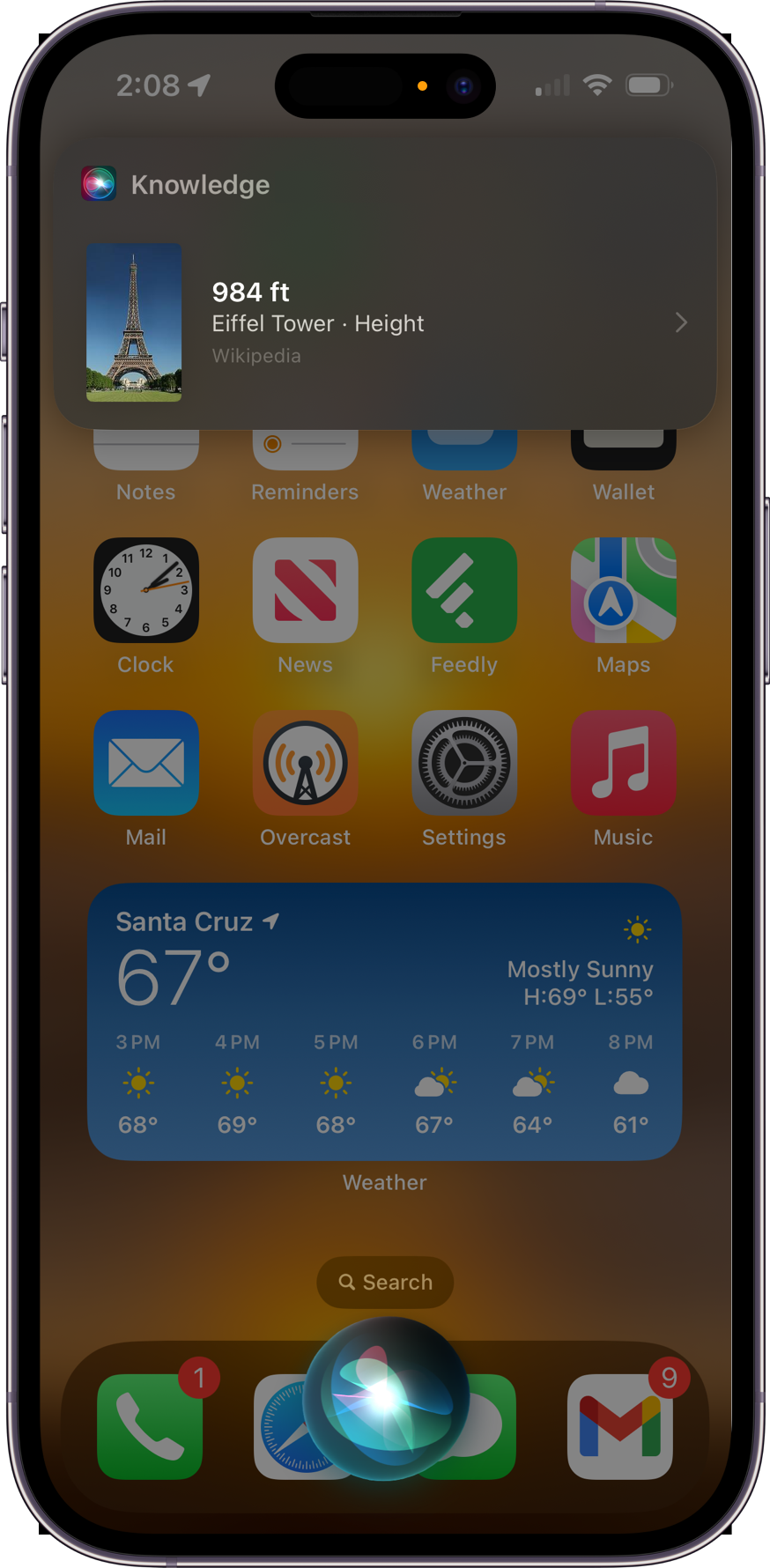
One of our other recent accomplishments was shepherding the “Back-to-Back Requests” feature into production. This means that once you have Siri’s attention, you can continue talking to it without saying its name again. For example, in the interaction below I said “Siri, how tall is the Empire State Building,” and then “how about the Eiffel Tower?”:
(On mobile, swipe to see additional screens)
On iPhone 11 and later, you can even interrupt Siri while it’s talking, or speak over music, thanks to hardware and firmware support for echo cancellation.
These interruption and back-to-back request capabilities are on by default, rather than controlled via settings, as with Alexa and Google Assistant. To achieve this simplicity, we built machine-learned models that classify Siri-directed versus human-directed speech. Siri ignores the latter.